Las tendencias en PI Vision llevaban varios minutos congeladas. Los valores no se movían. Era una tarde de febrero y acababa de llegar el aviso del equipo de operaciones.
No era la primera vez que veía algo así. Casi siempre se resuelve con un reinicio del servicio y todos a casa. Lo que no sabía en ese momento es que el "reinicio rápido" se iba a convertir en una de las jornadas más largas que recuerdo en mi trabajo.
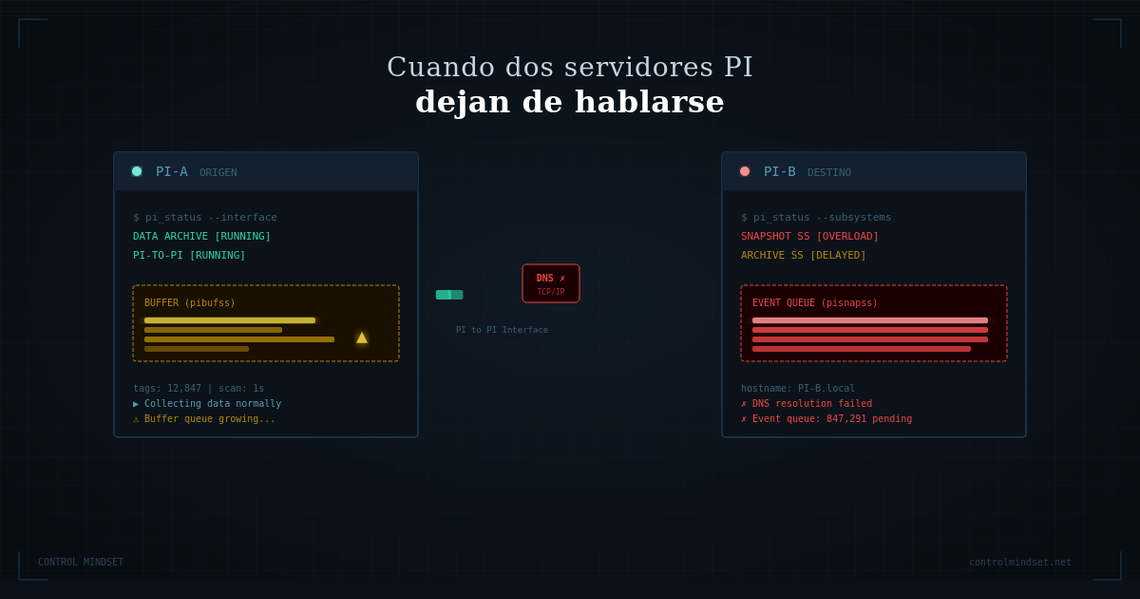
Resumen del incidente: Una falla de resolución DNS interrumpió la transferencia de datos entre dos servidores PI System conectados por interfaz PI to PI. La solución inicial (cambiar hostname por IP) restableció la conexión, pero desencadenó un segundo problema: una cola de snapshots creciendo sin control en el servidor destino, causada por consultas excesivas de un sistema secundario. La recuperación total tomó casi 24 horas, con un hueco de 14.5 horas de datos que se recuperó por backfill.
| Detalle | Valor |
|---|---|
| Duración total | ~24 horas |
| Hueco de datos | 14.5 horas (8:00 PM – 10:30 AM) |
| Sistemas afectados | PI to PI Interface, Snapshot Subsystem, Archive Subsystem |
| Causa raíz | Falla de resolución DNS + consultas excesivas de sistema secundario |
| Resolución | Cambio de hostname a IP + detención de interfaz secundaria + backfill |
Si nunca has tocado PI System, te lo cuento en una línea: es la columna vertebral de datos en tiempo real que usan muchísimas operaciones industriales. Sensores, controladores, históricos, dashboards — todo lo que el equipo de planta mira para saber qué está pasando, vive ahí dentro.
Y cuando dos servidores PI dejan de hablarse entre sí, lo que se rompe no es solo un enlace técnico. Se rompen las tendencias que el equipo usa para tomar decisiones, los reportes diarios, las alertas que avisan cuando algo se está saliendo de lo normal. La planta no se detiene, pero pierde uno de sus sentidos.
Este post es la cronología honesta de lo que pasó esa tarde y la siguiente. Por dónde fui, en qué me equivoqué, qué hipótesis seguí antes de dar con la verdadera causa. Es un caso real de mi trabajo, anonimizado donde corresponde — los nombres de los servidores y sistemas son ficticios, pero el incidente y los pasos son tal cual los viví.
Qué es PI to PI y por qué existe
Para entender por qué un problema que parecía un reinicio de cinco minutos terminó escalando como escaló, hay que ver primero cómo estaban hablando estos dos servidores entre sí.
Imagínate dos almacenes de datos que viven en servidores distintos. Uno está cerca de la planta, conectado a los instrumentos y controladores; lo voy a llamar PI-A. El otro está en otra red, quizás más segura, quizás dedicada a usuarios corporativos o a respaldo; ese es PI-B. Los dos guardan información del proceso, pero por razones de arquitectura no es buena idea que todo el mundo entre directamente al servidor que está pegado a la planta.
Aquí entra la interfaz PI to PI. Su trabajo es uno solo y lo hace bien: copiar datos de un servidor PI a otro, en tiempo real, vía TCP/IP. PI-A genera o recibe los datos, la interfaz los empuja a PI-B, y PI-B los guarda como si fueran propios. Una tubería de un solo sentido entre los dos almacenes.
¿Y por qué tomarse el trabajo de tener dos servidores en lugar de uno? Las razones varían según la planta, pero las más comunes son tres: redundancia (si uno se cae, el otro tiene los datos), separación de redes (la red de control y la red corporativa no deberían tocarse directamente, y PI to PI sirve de puente controlado entre ambas), y distribución de carga (que los usuarios que generan reportes y dashboards no le coman recursos al servidor que está atendiendo a la planta en tiempo real).
Hay un detalle de diseño que vale la pena mencionar porque va a importar más adelante: la interfaz PI to PI es un proceso de un solo hilo. Eso significa que es sensible a la calidad de la red entre los dos servidores y a la responsividad de cada uno. Si uno de los dos lados respira mal, la transferencia entera se resiente. No es un bug, es así por diseño — pero conviene tenerlo en mente.
Lo que esa tarde parecía una caída de servicio iba a terminar siendo bastante más incómodo que eso.
Timeline de referencia rápida
| Hora | Evento |
|---|---|
| 17:05 | Detección: tendencias congeladas en PI Vision |
| 17:15 | Reinicio de servicios PI to PI en PI-A — sin efecto |
| 17:30 | Reinicio de PI-B — se aplica parche KB5048661 pendiente |
| 17:45 | PI-B arriba, pero PI to PI no reconecta |
| 18:00 | Prueba de ping por hostname falla, por IP funciona — hallazgo de DNS |
| 18:15 | Se edita configuración de PI to PI: hostname → IP directa |
| 18:20 | Conexión restablecida, buffers empiezan a vaciarse |
| 18:30 | Cola de snapshots en PI-B crece exponencialmente |
| 20:00 | Se identifica sistema secundario con consultas excesivas |
| 20:15 | Se detiene interfaz del sistema secundario — cola empieza a bajar |
| ~02:00 | Cola llega a cero, interfaces reactivadas |
| 10:30 | Backfill completado, sistema 100% operativo |
Nota: los horarios son aproximados y reconstruidos de memoria y registros parciales.
Lo primero que intenté (y por qué no funcionó)
Mi primer instinto fue el de siempre: reiniciar los servicios de PI to PI en PI-A. Si la interfaz se quedó colgada, lo más probable es que el servicio esté en mal estado y un reinicio limpio lo devuelva a la vida. Lo hice. No funcionó. El error que recibí decía que no había conexión con PI-B.
Eso ya era extraño. Si PI-A no podía hablar con PI-B, el problema no estaba en el servicio que acababa de reiniciar — estaba más allá. Salté entonces al servidor destino para reiniciarlo también. Y aquí cometí, sin saberlo, un error que me iba a costar caro las siguientes horas.
Cuando reinicié PI-B, Windows aplicó un parche pendiente que llevaba días esperando ese reinicio: KB5048661, una actualización de seguridad de Windows Server 2019. No fue una decisión consciente de instalar el parche en medio del incidente — el parche ya estaba descargado, solo le faltaba el reboot. Y el reboot se lo di yo, pensando que estaba haciendo otra cosa.
El servidor volvió. PI-B respondía a ping, los servicios arriba, todo aparentemente normal. Pero la interfaz PI to PI seguía sin reconectar. Y ahora, además del problema original, tenía una variable nueva en la mesa: ¿el parche cambió algo? ¿la actualización tocó la configuración de red?
Cuando estás en medio de un troubleshooting, lo último que quieres es introducir variables nuevas que no controlas. Yo acababa de hacer exactamente eso.
El hallazgo: no era el servicio, era el DNS
Después de descartar lo obvio, empezamos a mirar más abajo en la pila. Probé hacer ping desde PI-A hacia PI-B usando el hostname. Falló. Probé con la IP directa. Funcionó. Ahí estaba.
Algo en la resolución de nombres se había roto. PI-A no podía traducir el nombre de PI-B a su IP, y como el archivo de configuración de la interfaz PI to PI usaba el hostname, la conexión moría antes de empezar. La solución provisional fue simple: editar el archivo batch del PI to PI Interface y reemplazar el hostname por la IP. Guardé, levanté la interfaz, y la conexión se restableció. Los buffers que llevaban horas acumulando datos en PI-A empezaron a vaciarse hacia PI-B.
Y ahora viene la parte honesta: nunca llegué a determinar con certeza qué cambió en el DNS o si el reinicio del parche tocó algo de la configuración de red. La hipótesis más razonable es que sí, que algo en ese reinicio alteró la resolución de nombres, pero no tengo evidencia dura que lo demuestre. Lo que sí pude verificar es que la resolución por hostname no funcionaba, y que usando IP directa sí. A veces los troubleshootings cierran así, con una solución que funciona y una causa probable que nunca terminas de confirmar al 100%. Más adelante, cuando todo estuviera estable, el equipo de TI revisaría la configuración de DNS con calma. En el momento, lo que importaba era que los datos volvieran a fluir.
Y por un rato pensé que ya estaba.
El segundo problema: la cola que no paraba de crecer
Acá viene la parte que más me sorprendió de todo el incidente, y la que más me sirvió para entender PI System de verdad.
Con la conexión restablecida, los datos empezaron a transferirse de PI-A hacia PI-B. Pero algo no estaba bien: la cola de snapshots en PI-B comenzó a crecer de manera exponencial. No bajaba, no se estabilizaba. Subía y subía. Se sumó al troubleshooting una consultora externa con experiencia profunda en PI, y entre los dos empezamos a entender qué estaba pasando.
Antes de seguir, déjame aclarar algo que es fácil confundir y que yo mismo confundí en su momento: en PI System hay dos lugares distintos donde los datos pueden acumularse cuando algo sale mal, y están en servidores distintos.
Por un lado está el buffer del origen, que vive en PI-A. Cuando PI-B está caído o inalcanzable, los datos que la interfaz PI to PI quería enviar se quedan acumulados acá, esperando que el destino vuelva. Funciona como una sala de espera del lado del emisor: cuando el receptor abre la puerta, todo el mundo entra de golpe.
Por otro lado está la event queue del destino, que vive en PI-B. Es el lugar donde el Snapshot Subsystem encola los eventos antes de pasarlos al Archive Subsystem para guardarlos definitivamente. Funciona como una bandeja de entrada: si llegan más cartas de las que el receptor puede abrir, la pila empieza a crecer.

Lo que estaba pasando era esto: la sala de espera de PI-A se había vaciado de golpe sobre la bandeja de entrada de PI-B, y encima de eso, había algo más en PI-B que estaba sobrecargando esa bandeja en paralelo. Los datos no estaban perdidos, estaban en el lugar equivocado y al ritmo equivocado.
La consultora sugirió reiniciar Snapshot Subsystem y Archive Subsystem, asegurando previamente el respaldo de los archivos snap. Lo hicimos. Llegó un paquete de datos a PI-B, lo cual era buena señal. Pero la cola seguía creciendo.
Algo más estaba metiendo presión en ese servidor.
Mirando los procesos con calma, encontramos al culpable: una base de datos operacional secundaria estaba haciendo consultas masivas al PI-B. No era un atacante ni un bug — era un sistema legítimo, configurado hacía tiempo, que en condiciones normales funcionaba bien. Pero en este momento, con PI-B intentando procesar el backlog acumulado del buffer de PI-A y además atender estas consultas, simplemente no daba abasto. Cada consulta entraba a la cola, se sumaba a los eventos pendientes, y la pila crecía más rápido de lo que el servidor podía vaciarla.
Detuvimos esa interfaz en particular. Y la cola empezó a bajar.
Una cosa que nunca llegué a determinar con certeza: si esas consultas de la base secundaria ya estaban ahí desde antes y solo se hicieron visibles cuando el servidor entró en estrés, o si eran un patrón que apareció durante la recuperación. Es la clase de pregunta que solo se responde con monitoreo histórico que en ese momento no teníamos a mano.
La recuperación y el hueco de 14 horas
La cola tardó un rato en llegar a cero, pero llegó. Reactivamos las interfaces una por una, las reconfiguramos para que volvieran a usar hostname (porque a esas alturas el problema de DNS ya estaba resuelto del lado de TI), y los datos empezaron a fluir con normalidad.
Pero quedaba un detalle. Entre las 8 de la noche del primer día y las 10:30 de la mañana del segundo, había un hueco. Catorce horas y media en las que PI-B no había recibido datos del proceso. No era catastrófico — los datos estaban sanos en PI-A, que nunca dejó de capturar — pero había que traerlos al destino para que las tendencias y reportes que dependían de PI-B tuvieran continuidad histórica.
La recuperación se hizo con un backfill desde PI-A: un proceso que toma los datos historizados del origen y los inserta en el destino con sus marcas de tiempo originales. Tardó un poco más de una hora. Cuando terminó, las tendencias se rellenaron, los reportes volvieron a cuadrar, y el sistema quedó completamente operativo.
Mirando hacia atrás, entre la primera alerta y el "todo verde" pasaron casi 24 horas.
Qué me llevé de todo esto
Cuando la adrenalina baja y uno puede mirar el incidente con calma, aparecen las cosas que valen la pena recordar. Estas son las cuatro que me quedaron rondando:
El instinto de "reiniciar primero" tiene un costo escondido. Cuando reinicié PI-B para descartar la hipótesis del servicio, sin querer apliqué un parche pendiente y metí una variable nueva en medio del troubleshooting. En sistemas críticos, antes de reiniciar conviene saber qué cambia con ese reinicio.
Ya no doy reboots a ciegas en servidores que llevan días sin reiniciarse: primero reviso si hay actualizaciones pendientes, qué hacen, y decido si quiero esa variable adentro o no.
Hostname versus IP es una decisión que parece menor hasta que importa. Configurar interfaces críticas para que dependan de DNS te ahorra trabajo el día uno y te lo cobra el día que DNS falla. No estoy diciendo que IP directa sea siempre mejor — es un tradeoff.
IP directa es frágil ante cambios de red; hostname es frágil ante cambios de DNS. Lo importante es tener esa decisión consciente y no por inercia.
Buffer y event queue se confunden fácilmente, y entender la diferencia cambia cómo diagnosticas. Los datos rara vez están "perdidos" en PI System. Casi siempre están en algún lado, esperando.
Saber dónde mirar — buffer del origen, event queue del destino, archives — es la mitad del trabajo. La otra mitad es saber qué procedimiento aplica en cada caso, porque vaciar un buffer y vaciar una event queue no se hacen igual.
Un incidente raramente tiene una sola causa raíz. En este caso fueron al menos dos cosas concurrentes: un fallo de resolución de nombres por DNS, y consultas excesivas desde un sistema secundario que saturaron la cola justo cuando el servidor estaba más vulnerable.
Si me hubiera quedado con la primera causa aparente, habría cerrado el incidente antes de tiempo y el sistema probablemente habría vuelto a caer poco después. Los incidentes reales suelen ser combinaciones de cosas que por separado serían manejables, pero juntas se potencian.
Acciones implementadas después del incidente
- Se documentó un procedimiento de reinicio para servidores PI que incluye verificación de parches pendientes antes de ejecutar el reboot.
- Se revisó la configuración de DNS para ambos servidores y se agregaron entradas estáticas en el archivo hosts como respaldo.
- Se configuró monitoreo de los contadores de performance del Snapshot Subsystem y Archive Subsystem, con alertas por umbral para detectar crecimiento anormal de la cola de eventos antes de que escale.
- Se estableció una política de revisión periódica de las interfaces secundarias que consultan datos del PI, para identificar cargas excesivas en condiciones normales.
Cierre
Este fue uno de esos días en los que aprendes más en doce horas que en doce semanas de operación normal. No es agradable mientras pasa — la sensación de no entender qué está roto en algo que debería ser estable es bastante incómoda — pero es el tipo de experiencia que te queda guardada para la próxima.
Si trabajas con PI System y has pasado por algo parecido, me interesa saberlo. Y si recién estás conociendo este mundo, espero que esto te haya servido como una ventana a cómo se ve un día complicado en una sala de control.
Lección de cierre
En sistemas industriales, una señal congelada, una cámara lenta o una interfaz caída rara vez se explican con una sola causa. El valor está en ordenar síntomas, evidencias, cambios recientes y dependencias técnicas antes de intervenir.
Este artículo tiene fines educativos. Los casos pueden estar simplificados o anonimizados y no representan a ninguna empresa, cliente o proveedor.
Member discussion